Data center risk management: Why exactly do we have data center set points?

Dr Stu Redshaw Co-founder and CTIO – Chief Technology and Innovation Officer, EkkoSense, shares his latest views on data center risk management strategies
What’s the purpose of set points on cooling units. Why exactly do we have them? More to the point, do we really need them at all?
Traditionally we’ve always had a hierarchy of cooling temperature levels – first, the set point – then the warning level, and ultimately an action level. Some data center teams of course still blast everything with cold air to remove the need for warnings and actions completely. But that’s clearly an unsustainable option. Of course it makes no sense to keep on over-cooling from a financial and ESG perspective, but many still see this approach as an effective data center risk management insurance policy, effectively saving themselves from all the inevitable aggravation and recriminations that come their way should a critical SLA be breached.
Bypassing set point concerns through over-cooling is clearly sub-optimal from an optimisation perspective, however over-focusing on set points can be equally counter-productive. We need to move away from comfort cooling, but it’s a mistake to think that simply establishing set points will give us the certainty and protection we’re looking for.
The reality is that our industry can be overly-defensive about cooling thresholds that analysis shows are frequently imprecise. We need to recognise that we’re not building spaceships or working to pharma batch processing standards where deviations of a fraction of a percentage are unacceptable – we’re just running data centers whose thermal performance is impacted by a wide range of factors each and every day. There’s always going to be some element of give and take.
That’s certainly the case when it comes to data center set points. Simply entering a number in the set point box won’t give you a guarantee of a constant temperature – in fact that number often has very little to do with reality. At every stage there’s imprecision: the cooling manufacturer might have a hidden +/- 1°C within a unit’s design; many sensors can run at +/- 3°C; monitored temperatures can vary depending on where sensors are placed, while over-cooled data centers typically have much greater temperature variations than warm ones.
So in the end we’re left with a seemingly important temperature value that is almost certainly not as reliable as we think. What should be a very simple measure starts to become much more complicated. So why then do we have set points?
Typically data center operations tend to build up their own series of set point, warning and action points as a mechanism to deal with the fact that they don’t always know exactly how their rooms are performing on a real-time basis. Because IT operations are so acutely averse to risk in terms of temperatures, over-cooling is often considered a sensible data center risk management precaution. No wonder there are so many cold data centers, when the alternative is waiting for arbitrary temperature set point SLAs to be breached or being surprised by potentially late BMS alarms.
That’s why it’s so important to be able to identify potential thermal issues early, diagnose them quickly, and resolve potential problems before they can start to impact SLAs. At EkkoSense we address this by adopting a far more granular approach to environmental monitoring and optimization. We recommend that all IT racks should have at least one thermal sensor on their inlet air surface, along with real-time tracking of cooling duty performance for any CRAC/AHU units. Monitoring and analysing at this level lets us build a complete thermal picture of real-time temperature performance in 3D across all our sites.
In addition, advanced capabilities such as Cooling Anomaly Detection also enable operations teams to focus in on any drift from control set points and alert any abnormal changes in performance. This ability to highlight airflow and fan failures, cooling and refrigeration faults, machine faults, and cooling unit over or underloads ahead of a potential failure makes it much easier for data center teams to get on top of potential issues.
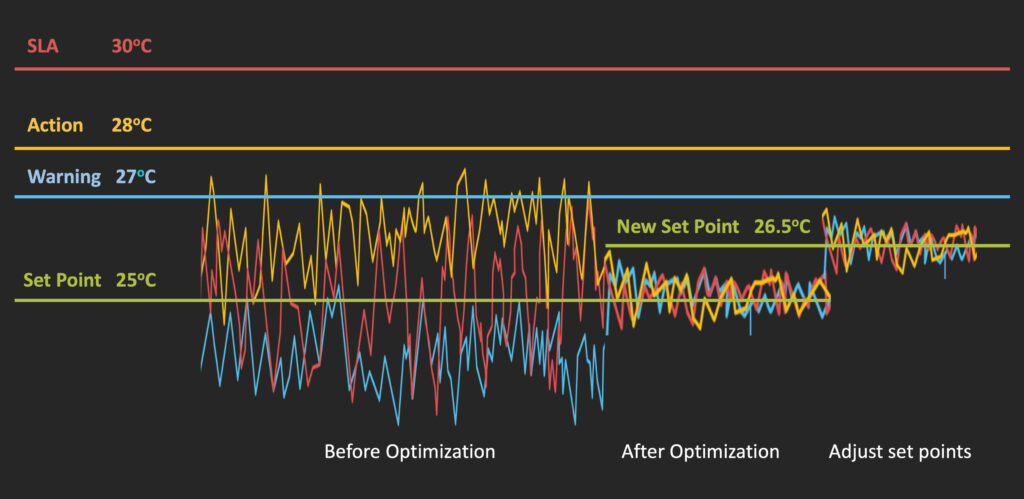
It’s important not to focus too much on the specific set point number, when it’s relative trend of the relationship between that number and the room that matters. Once you’ve got this kind of data centre risk management approach and this level of insight into potential cooling issues, you can start to adopt a much more proactive approach to data centre optimisation that recognises that energy savings don’t just revolve around set point changes. Rather than fixate on the set point numbers – you’re monitoring those anyway – instead you get to the stage where your continuous optimisation and behaviour effectively becomes the set point itself. What matters is that you’re working with set points that you can actually do things with.
Read more EkkoSense data center optimization expert blogs, or contact the author, Dr Stu Redshaw to continue the conversation. Alternatively, view an instant video of EkkoSense data center visualization here.